
Data Visibility Evolution
Part 1: Introduction and Use Cases

Published by: Hesam Shams
Jan 17, 2025
This post was also published on Medium. You can find it here: Data Visibility Evolution - Part 1: Introduction and Use Cases
In this first part of the blog series on Data Visibility, I discuss what data visibility means and why it’s essential in today’s data-driven world. Also, I will explore some real-world use cases to illustrate how data visibility are crucial to make informed decisions, optimize operations, and adapt to market changes. Future posts of this series will dive deeper into current processes which are temporary remedies and how our innovative and permanent solution at Gebra Tech reshapes the data traceability without changing current operations.

Introduction:
As a data scientist, I had the opportunity to work in different environments, fast-paced startups and large, well-established corporations. Despite the differences in size, culture, and resources, I noticed a surprisingly common challenge: lack of data visibility. In every role, I found myself spending more time untangling the web of disconnected data sources than analyzing the data itself.
At one startup, I spent days just trying to put together customer data from different platforms. Each platform had its own format and quirks. Later, I discovered that some critical datasets were outdated or defective. In another case, at a large corporation, a simple request to identify if an entry is legitimate or outlier in customers’ ledgers turned into a multi-week hassle involving countless emails, manual exports, and follow-ups with different teams.

The frustration was universal. Valuable time was wasted tracking down data, verifying its accuracy, and resolving discrepancies. Beyond the frustration of inaccessible or outdated data, a deeper issue often emerges: the lack of data traceability and a true source of information. When data origin, transformations, or updates can’t be tracked, it becomes difficult to trust the insights derived from it. Decisions made on inconsistent or unverifiable data can lead to costly errors, missed opportunities, and inefficiencies. Data visibility is more than access. It ensures everyone in an organization can confidently rely on accurate, consistent, and traceable information to drive impactful decisions.
Data visibility is essential, not just a buzzword. It is about creating a seamless flow of reliable and actionable data across an organization. This empowers everyone, from analysts to executives. In this blog post, I’ll explore why data visibility matters, how it drives both business and technical innovation, and what it takes to achieve it in practice.
What is Data Visibility?
In an era where data is generated in overwhelming volumes, companies globally are realizing that raw data alone is not enough. What organizations need is data visibility—the ability to view, understand, and use data seamlessly across their entire business landscape. Without data visibility, even the most data-rich companies struggle to make timely, informed decisions, missing opportunities to innovate, optimize, and stay ahead of the competition.
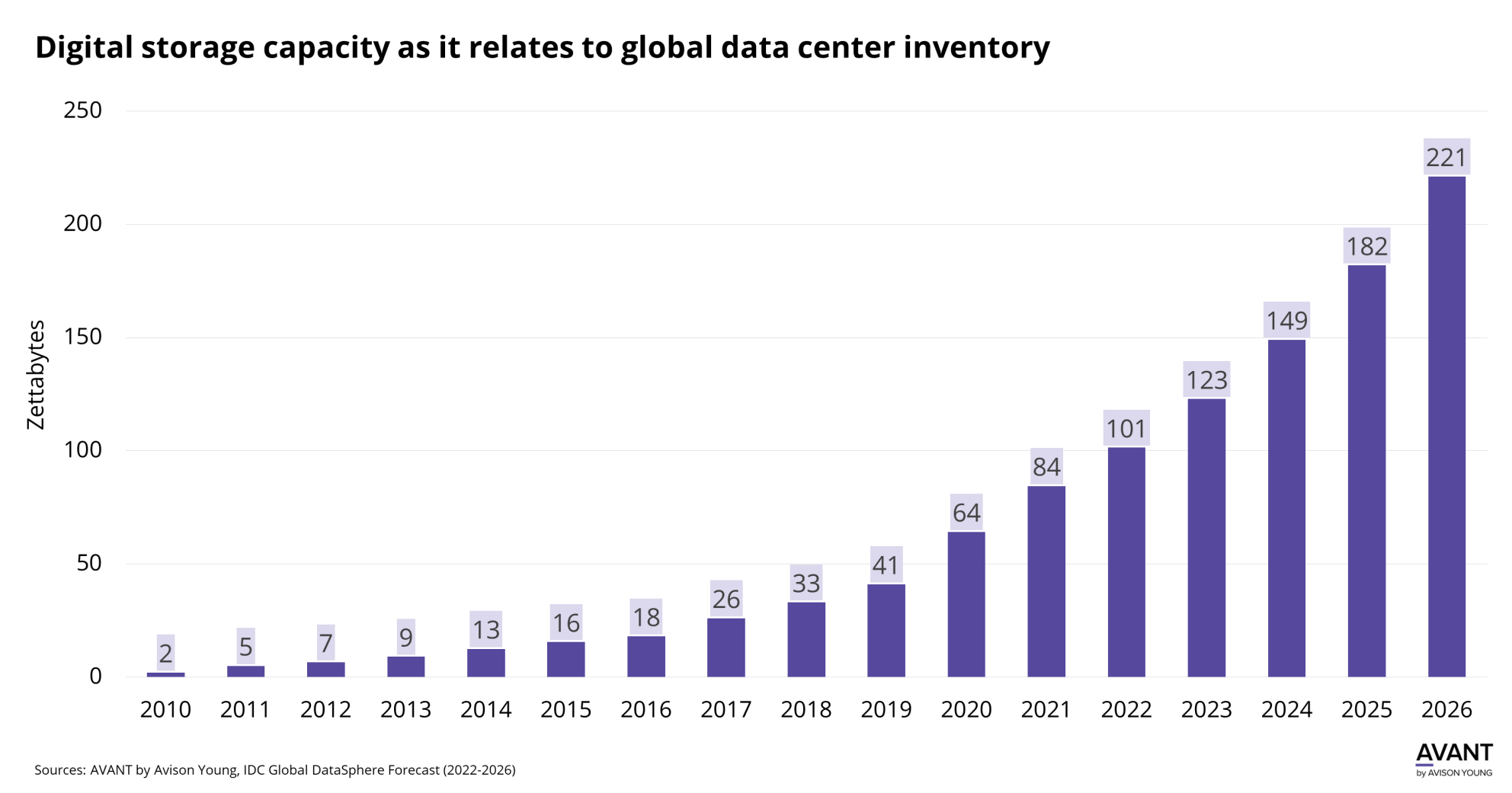
Consider this: By 2026, the global data sphere is expected to grow to 221 zettabytes (more than double in size at 2023) [1], but without an effective way to harness this data, much of its potential will remain unfulfilled. Data visibility isn’t just about having access to data; it’s about connecting that data in a way that’s accessible, meaningful, and actionable. Imagine if every team member, from developers to executives, could confidently use and rely on a unified view of data to drive insights and decisions. This level of access turns data into a strategic asset, enabling everyone in the organization to work from the same playbook and make decisions with clarity and agility.
The need for data visibility extends beyond individual organizations. In industries where collaboration and partnerships are vital—such as supply chain, healthcare, and financial services—the ability to securely share and connect data across entities is key to success. Misaligned or siloed data across organizations leads to inefficiencies, errors, and missed opportunities.
In the trucking industry, where efficiency is critical to supply chain success, a shocking 40% of truck miles in the U.S. are driven empty (deadhead). This statistic hasn’t improved since the 1990s, despite technological advancements. This inefficiency (deadhead truck) is rooted in disconnected and siloed data [2], leading to significant losses for all involved actors. For example, a trucking company fulfills a delivery to a warehouse but lacks visibility into nearby available loads for its return trip. The truck drives back empty, wasting fuel, increasing wear and tear, and contributing to unnecessary greenhouse gases emissions. Shippers and brokers, meanwhile, miss out on available capacity, causing delays in their operations, while retailers and manufacturers keep up the burden of higher logistics costs. Data visibility can transform this dynamic entirely. By connecting related brokers, shippers, and carriers securely in real time, trucks can be utilized efficiently, reducing costs, minimizing environmental impact, and ensuring timely deliveries. This creates a win-win situation for actors where trucking companies boost profitability, businesses reduce operational costs, and customers experience better service.
For data scientists and machine learning (ML) engineers, data visibility means accurate datasets that drive reliable predictions and analytics. For business stakeholders, it means the confidence to make data-backed decisions that drive the company forward. This blog post explores why data visibility is more than a technical concern. It is a competitive advantage that affects every level of business and a key enabler for today’s most innovative companies.
The Business Cases for Data Visibility:
In today’s fast-paced business world, data visibility is crucial. It's not just a technical advantage; it’s a strategic necessity. Companies that embrace data visibility are better equipped to make informed decisions, optimize operations, and adapt to market changes. Without it, even the most data-rich organizations risk falling behind due to inefficiencies, missed opportunities, and delayed responses. In the following paragraphs, we discuss real-world use cases and practical examples to illustrate the challenges caused by a lack of data visibility. We also explore how data visibility, powered by strong traceability, improves decision-making, reduces costs, enhances customer experience, and speed up innovation for machine learning teams.
Empowering Decision-Making Across the Organization
Data visibility ensures that stakeholders at all levels have access to accurate, real-time data to drive decisions. For example, consider a marketing team launching a campaign to promote a new product. Without visibility into inventory and supply chain data, they might promote a product that’s out of stock in key regions, leading to frustrated customers and lost revenue. On the other hand, real-time data visibility would allow the team to adjust their campaign strategy dynamically, targeting locations with adequate inventory and ensuring a uninterrupted customer experience. Traceability ensures that decision-makers trust the data, reducing the risk of costly mistakes.
Saving Costs and Driving ROI
Inefficient data processes often lead to hidden costs that can add up quickly. Imagine a manufacturing company trying to forecast demand using outdated sales data. The production team overestimates demand, resulting in excess inventory that locks up cash flow and leads to higher storage costs. Meanwhile, the ML team spends weeks cleaning and adjusting inconsistent data from multiple sources to create demand forecasting models.
A lack of traceability causes confusion. Teams cannot tell which data is current, accurate, or relevant. With better data visibility and traceability, the company could ensure that sales data is both up-to-date and properly attributed to its sources. This traceability reduces uncertainty, allowing production teams to generate accurate forecasts in real-time and minimizing waste, while the ML team can work with true sources of data, saving time and resources.
Enhancing Customer Experience
Data visibility isn’t just an internal benefit; it directly impacts customer satisfaction. For instance, a data scientist at an e-commerce company discovers that delays in syncing warehouse data with the website result in customers ordering out-of-stock items. Not only does this lead to cancellations and refunds, but it also damages trust in the brand. Without traceability, it’s difficult to pinpoint where the breakdown occurred—was it outdated warehouse records, delayed syncing, or human error?
By integrating data systems and ensuring real-time updates with traceability, the company can track every step of the process. The website displays accurate product availability because it’s backed by traceable data flows from warehouses, improving the shopping experience and retaining customer loyalty. Traceability ensures transparency, reinforcing trust between the company and its customers.
Accelerating Innovation for ML Teams
For data scientists and ML engineers, lack of visibility often translates to missed opportunities for impactful insights. In one example, an ML team at a logistics company tries to build a route optimization model but struggles to access up-to-date data on delivery times, traffic patterns, and driver availability. After weeks of piecing together separated data, they find that the model performs poorly because the data wasn’t consistent or timely.
Data traceability would eliminate this inefficiency by allowing the team to track each dataset’s origin, transformations, and update frequency. With consistent and real-time traceable datasets, the ML team can build more accurate models faster. Traceability ensures that all inputs are reliable and reduces the time spent debugging or cleaning data, enabling faster deployment of solutions that save time and money.
A Competitive Edge in a Data-Driven World
Businesses that leverage data visibility gain a significant advantage over competitors. They can respond to market changes quickly, identify emerging trends, and innovate faster. For example, a supply chain company with full data visibility might use real-time data from its warehouses, trucking fleet, and retail partners to identify a bottleneck in its process. Let’s say a delay in receiving raw materials at a manufacturing plant is threatening to disrupt production schedules. With data traceability, the logistics team can immediately verify the cause of the delay. It could be a supplier issue, a transportation holdup, or incorrect inventory data.
By tracking the data’s path through the supply chain, they can take corrective actions like rerouting shipments or adjusting production priorities. Retail partners are also provided with updated timelines backed by traceable data, allowing them to adjust inventory planning confidently. A competitor lacking visibility might only notice the issue when production halts, damaging relationships with partners. This ability to proactively identify and address bottlenecks doesn’t just save costs; it ensures smoother operations, strengthens customer trust, and provides a critical competitive edge in the current fast-moving market.
This is just the beginning! Stay tuned for Part 2, where we’ll analyze the current solutions for data visibility and uncover their limitations. Don’t miss out! Subscribe to my blog for updates.
References
[1] - https://www.avisonyoung.us/w/global-dataspheres-rapid-growth-expected-to-drive-demand-on-data-centers
[2] - "Transportation Statistics Annual Report 2023" (2023), https://doi.org/10.21949/1529944
